


Criminaliteit in een rood vierkantje, hoe overzichtelijk wil je het hebben. Maar of het ook werkt is een tweede. Wetenschappelijk bewijs is er niet, wel interpretatiefouten en etnische bias. Siri Beerends over onder meer het Criminaliteits Anticipatie Systeem en Systeem Risico Indicatie.
Nederland was er als de kippen bij met predictive policing. In 2017 waren we het eerste land ter wereld waar een predictive policing systeem nationaal werd uitgerold. Het oer-Hollandse, in Nederland ontwikkelde Criminaliteits Anticipatie Systeem (CAS) belooft criminaliteit te voorspellen, zodat de politie preventief kan ingrijpen.
CAS laat een kaart van Nederland zien, opgedeeld in vierkantjes van 125 bij 125 meter. Een rood kader geeft aan in welk gebied een verhoogde kans is op ‘high impact crimes’ zoals woninginbraken, overvallen en straatroven.
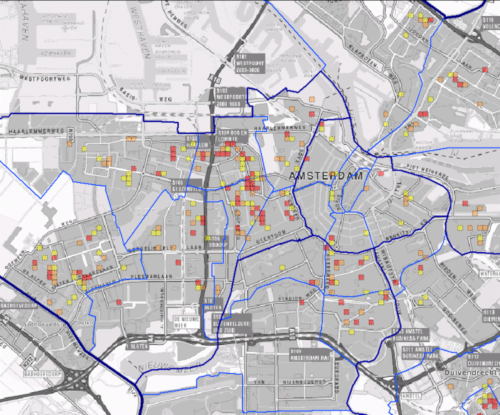
Regio Amsterdam in het Criminaliteits Anticipatie Systeem
De algoritmen van CAS gebruiken historische criminaliteitsdata in combinatie met een berg andere data, bijvoorbeeld inkomensgegevens en het aantal slijterijen in een wijk, om te voorspellen waar een verhoogde kans is op criminaliteit. Naar aanleiding van de geselecteerde wijken wordt bepaald waar meer agenten naartoe moeten en waar vaker een politiewagen moet rondrijden.
Predictive problems
Criminaliteit in een rood vierkantje; hoe overzichtelijk wil je het hebben. Maar of het ook echt werkt is een tweede. De Politieacademie deed onafhankelijk onderzoek naar de effecten van CAS en vond geen bewijs dat de criminaliteit daalt. De werking van CAS is nooit wetenschappelijk bewezen en de effectiviteit van het systeem laat zich moeilijk meten.
Wanneer CAS bijvoorbeeld voorspelt dat in een bepaalde wijk een verhoogde kans is op criminaliteit en de politie daar meer surveilleert, kan vervolgens elke aangifte geïnterpreteerd worden als een door CAS voorspeld incident. En wanneer er sprake is van weinig criminaliteit in een aangewezen risicogebied, kan dit worden afgeschreven als succesvolle preventie met dank aan de voorspelling van CAS. Of de effecten ook daadwerkelijk het gevolg zijn van CAS valt niet te controleren.
Hoewel de politie erkent dat de werking van CAS niet is bewezen, denken zij dat het systeem een positief effect heeft omdat het in ieder geval meer inzicht geeft dan enkel historische criminaliteitsgegevens.
De algortimen van CAS geven ordehandhavers inderdaad meer inzicht, alleen zijn deze inzichten nogal eens onderhevig aan interpretatiefouten, feedbackloops en etnische bias. Zo blijkt het interpreteren van gegevens uit CAS ronduit ingewikkeld te zijn. Neem bijvoorbeeld woninginbraken: volgens het systeem gebeuren deze het vaakst tussen zes en acht uur ‘s ochtends, maar dat kan ook het tijdstip zijn waarop mensen ontwaken en ontdekken dat er is ingebroken.
Het verwarren van correlatie en causaliteit is een terugkerend probleem bij algoritmische voorspellingen. Algoritmen meten over het algemeen geen causaliteit maar correlatie: het tegelijk voorkomen van twee of meerdere verschijnselen. Als dat maar vaak genoeg gebeurt, gaat het algoritme er vanuit dat er een relatie is en neemt hij deze in het vervolg altijd mee in zijn berekening. Of de relatie er ook echt is en hoe die tot stand is gekomen valt niet te achterhalen, terwijl dit voor de mensen die met een algoritmische voorspelling te maken krijgen nu juist de meest relevante informatie is.
Algoritmen zijn goed in algemene conclusies en structurele patronen. Maar criminaliteit is een ingewikkeld samenspel van variabelen die onmogelijk allemaal in een algoritmisch model of rood vierkantje passen. Door ze alsnog in een algoritmisch model te persen en naar dit model te handelen, ontstaan er biasses en misplaatste verbanden waar vooral minderheden de dupe van blijken te zijn. Virginia Eubanks laat dat zien in haar boek Automating inequality. Big data reproduceren onregelmatigheden en afwijkingen in datasets, waardoor de uitkomsten een ongelijkmatige sociale impact hebben.
In het geval van predictive policing gebeurt dat door de manier waarop het systeem historische criminaliteitsdata gebruikt. Deze data kunnen biased zijn, bijvoorbeeld doordat minderheden vaker aan politiecontroles worden onderworpen. Als een algoritme daar patronen in gaat zoeken, kan diezelfde bias uit het voorspellende model rollen.
In het wetenschappelijke rapport “Boeven vangen” staat beschreven hoe zo´n bias tot stand komt:
De politie creëert door de dominante manier van kijken (profileren) een werkelijkheid (bepaalde bevolkingsgroepen zijn meer crimineel dan andere bevolkingsgroepen) die zij bevestigt op basis van data (criminaliteitsdata) die het resultaat zijn van die dominante manier van kijken en daaruit voortvloeiende werkelijkheid, en dat leidt weer tot een verdere eenzijdigheid in de manier van kijken.
In de praktijk betekent dit dat wijken waar veel gesurveilleerd wordt prominenter naar voren zullen komen in de criminaliteitscijfers. De extra aandacht vergroot de bestaande problemen verder uit, wat de basis vormt voor nieuw beleid, dat op zijn beurt het negatieve beeld verder versterkt. Predictive policing werkt op die manier als een voorspelling die zichzelf waarmaakt.
Ook vergroot de extra politieaandacht de kans op etnisch profileren. In de aangewezen risicogebieden worden veelal flex-agenten ingezet. Deze hebben in vergelijking met traditionele wijkagenten minder sociale en contextuele kennis over de risicogebieden, waardoor zij eerder geneigd zijn om terug te vallen op vooroordelen en etnische profilering.
Overheid algoritmiseert vrolijk verder
De Wetenschappelijke Raad voor Regeringsbeleid waarschuwde in 2016 al dat big data toepassingen kunnen leiden tot een groeiende sociale ongelijkheid. Als we niet ingrijpen zou er op lange termijn een cumulatief nadeel ontstaan in de vorm van discriminatie en oneerlijke behandeling van bepaalde bevolkingsgroepen in de maatschappij.
In plaats van de algoritmische problemen aan te pakken, steekt de overheid zijn kop in het zand en implementeren zij het ene na het andere risicovoorspellende algoritme.
Eerder dit jaar schreven we al over Systeem Risico Indicatie (SyRI) dat op zoek gaat naar patronen in data om risicoburgers te onderscheiden. Het is onbekend welke gegevens het systeem gebruikt, welke analyses het uitvoert, wie de gegevens te zien krijgen, wat iemand tot een risicogeval maakt en of de gebruikte gegevens juist zijn.
De risicoprofilering van onverdachte Nederlanders is volgens burgerrechten organisaties in strijd met het Europees Verdrag voor de Rechten van de Mens. Daarom sleepten zij begin dit jaar de Nederlandse staat voor de rechter. Deze zaak loopt nog.
De aanname is dat iemand die afwijkt van het gemiddelde een fraudeur is.
Ook op gemeentelijk niveau worden risico indicatiesystemen gretig ingezet. Lekstroom, Middelburg, Veere, Vlissingen en Nissewaard gebruiken data-analyse om te bepalen welke verdachte burgers ze gaan onderzoeken. De software is getraind met data van geregistreerde fraudegevallen bij sociale diensten. In de database zijn honderden variabelen opgenomen, bijvoorbeeld of iemand in een psychiatrische inrichting heeft gezeten. In de data wordt gezocht naar mensen met een afwijking ten opzichte van het gemiddelde. De aanname is dat iemand die afwijkt van het gemiddelde een fraudeur is. Een algoritme wijst de tien meest waarschijnlijke fraudegevallen aan, daarna gaan controleurs aan de slag om te bepalen of er ook echt gefraudeerd is.
Een ander voorbeeld is Dordrecht, waar een algoritme bepaalt welke spijbelaars een leerplichtambtenaar aan de deur krijgen en welke er vanaf komen met een waarschuwende brief. De computer gebruikt dertien variabelen waaronder onderwijsniveau, het postcodegebied van de school, en hoe vaak iemand van school wisselde.
Sommige gemeenten gaan zelfs nog een stapje verder en gebruiken algoritmen die op basis van gegevens over inkomen, werkloosheid, bijstand, eenoudergezinnen, vroegtijdig schoolverlaters, 65-plussers en koopkracht, straten aanwijzen waar een verhoogd risico is op leefbaarheidsproblemen. De algoritmen wijzen ook straten aan waar de bewoners te veel geld zouden verdienen voor leefbaarheidsproblemen, deze worden er door de wijkagent uitgefilterd. In de overige straten krijgen bewoners hulpverleners aan de deur met folders over subsidies en instanties. De bewoner krijgt niet te horen dat een algoritme zijn straat aanwees en de vrijwilliger weet niet waarom het algoritme hun adres koos.
Het op voorhand uitfilteren van rijke wijken is een schoolvoorbeeld van algoritmische ongelijkheid: alleen achterstandswijken zijn onderwerp van screening. De aanname dat leefbaarheidsproblemen en fraude niet voorkomen in vermogende kringen houdt de rijkere wijken buiten beeld.
Verleden is niet gelijk aan toekomst
Los van de biased data en ongelijkheidsproblematiek is er nog een ander fundamenteel probleem bij het voorspellen van criminele feiten en risicovol gedrag.
Het doel van het analyseren van grote hoeveelheden data is het voorspellen van gedrag zodat de overheid kan ingrijpen voordat een burger handelt. Precies daar ligt het probleem: niet wat jij doet bepaalt hoe de overheid naar jou kijkt, maar een voorspelling over wat jij van plan zou kunnen zijn, terwijl die voorspelling lang niet altijd klopt. De gegevens die jij via jouw digitale voetsporen achterlaat zeggen namelijk niet altijd iets over de keuzes die jij in de toekomst gaat maken, of het gedrag dat jij in de toekomst gaat vertonen.
Het beoordelen en benaderen van burgers vanuit hun gedragsgeschiedenis is oneerlijk omdat het de keuzes reduceert die mensen kunnen maken. Zij worden door algoritmen vastgepind op een aantal kenmerken met daaraan vastgekoppelde voorspellingen, en krijgen op grond daarvan vervolgacties en informatiestromen opgelegd. Daardoor worden zij doorlopend op hun oude identiteit aangesproken.
Tijd voor een wake-up call met flagged
Door hun aura van objectiviteit worden algoritmische voorspellingen als alwetende orakels gebruikt, terwijl er fouten in de data kunnen zitten, de data vooroordelen kunnen weerspiegelen en uit correcte data verkeerde conclusies kunnen worden getrokken. Gemeenten en overheden vinden het belangrijker om voorop te lopen met de nieuwste technologische snufjes dan de bestaande systemen te verbeteren.
Terwijl we in Nederland nog moeten wakker worden, liggen predictive policing systemen in Amerika hevig onder vuur. In New York, Chicago en Los Angeles werden vorige maand verschillende politieafdelingen aangeklaagd vanwege het niet transparant maken van hun algoritmen. Een speciale commissie gaat daar onderzoek doen naar de onbedoelde neveneffecten van predictive policing.
In Nederland hebben we nog een lange weg te gaan. Hier veegt de overheid alle problemen onder het tapijt met het argument dat risicovoorspellende algoritmen ontransparant moeten blijven omdat ze worden gebruikt voor de opsporing en vervolging van strafbare feiten.
Om de problemen omtrent predictive policing invoelbaar te maken ontwikkelde kunstenares Milou Backx in samenwerking met SETUP Flagged. De game is één van onze “Civil Weapons of Math Retaliation”;https://www.setup.nl/magazine/2018/01/civil-weapons-math-retaliation waarmee we de impact en macht van moraliserende algoritmen inzichtelijk maken.

Flagged by Milou Backx
Dit najaar verschijnt een wetenschappelijke publicatie van Siri Beerends (cultuursocioloog) en Dr. Remco Spithoven (Lector Maatschappelijke Veiligheid, Hogeschool Saxion) over techno-optimisme en de valkuilen van big data toepassingen in de veiligheidssector.
Op zondag 12 augustus konder bezoekers Flagged spelen tijdens het Playraum Urban Gaming Festival in Utrecht. Tijdens het spelen konden zij ervaren hoe het is als data jou aanstuurt en hoe de stad eruit ziet door de ogen van verschillende bevolkingsgroepen.
Siri Beerends is werkzaam bij SETUP
Dit verhaal is eerder geplaatst op de website van SETUP. SETUP wil een breed maatschappelijk debat stimuleren over de vraag hoeveel en welke besluitvorming we bereid zijn om van algoritmen te accepteren.
