


Het verbeteren van de toegang tot overheidsinformatie, transparant zijn over het handelen en verantwoording aan de samenleving afleggen, zijn belangrijke pijlers voor de Nederlandse overheid. Hier wordt concreet invulling aan gegeven door steeds meer (open) data proactief publiek beschikbaar te stellen. Bij het (breed) beschikbaar stellen van open data, speelt privacy een voorname rol. SDC-technieken en -tools kunnen dataprofessionals ondersteunen bij het beschermen van privacygevoelige gegevens.
Het breed beschikbaar stellen van overheidsdata kan alleen als dit op een verantwoorde manier gebeurt. Hierbij speelt de bescherming van de privacy van de betrokkenen een belangrijke rol. Zeker als het gaat om gevoelige gegevens over kwetsbare burgers. In de open data context, waarin de beschikbaar gestelde gegevens in principe toegankelijk zijn voor iedereen, inclusief mogelijke kwaadwillenden, is privacybescherming extra belangrijk. Het beschermen van datasets is niet alleen belangrijk in de context van open data, maar ook relevant voor andere soorten van datadelingen en –verwerkingen, bijvoorbeeld bij het delen van datasets tussen (overheids-)organisaties en voor datagedreven beleidsontwikkeling. Door de inwerkingtreding van de Algemene Verordening Gegevensbescherming (AVG) in 2018 is privacybescherming en het zorgvuldig omgaan met persoonsgegevens immers belangrijker geworden.
Tegelijkertijd zien we dat, doordat de hoeveelheid beschikbare data groter is dan ooit en razendsnel blijft groeien, de kans op privacyinbreuken steeds groter wordt. Dit komt doordat het enerzijds voor grotere datasets, met een groot aantal mogelijk afhankelijke attributen, moeilijker is om de risico’s die verborgen zijn in de dataset (de intrinsieke risicofactoren) te detecteren. Anderzijds maakt het beschikbaar komen van steeds meer en steeds grotere datasets het moeilijker om de risico’s die zich kunnen voordoen bij het combineren van de data met andere datasets (de extrinsieke risicofactoren) in te schatten. De genoemde risico’s kunnen ertoe leiden dat er (per ongeluk en/of in de toekomst) gevoelige informatie over personen in de dataset wordt vrijgegeven. Zo kunnen statistische onthullingsmethoden en datakoppelingen gebruikt worden om personen in de dataset te identificeren of (nieuwe) persoonlijke informatie over hen te achterhalen. Dit kan zelfs als direct identificerende gegevens zoals namen uit de data zijn verwijderd, met name door aanvullende informatiebronnen te gebruiken. De combinatie van beroep en woonplaats in een dataset kan bijvoorbeeld de identiteit van een persoon onthullen. Voor de combinatie ‘burgemeester’ en ‘Amsterdam’ is dit niet moeilijk, doordat dit eenvoudig (online) te achterhalen is. Het is dan bekend welke gegevens in de gedeelde dataset over de betreffende persoon gaan.
Statistische privacybeschermingsmethoden
Dergelijke onthullingen staan op gespannen voet met de AVG. Bij het beschikbaar stellen van data dient derhalve steeds zorgvuldig afgewogen te worden of deze bij hergebruik risico’s opleveren voor de privacy van de betrokkenen. Hiervoor zijn verschillende statistische privacybeschermingsmethoden beschikbaar, die ook wel Statistical Disclosure Control technologies (SDC) genoemd worden. Hierbij gaat het zowel om statistische beschermingsmethoden, modellen en procedures (samen: SDC-technieken) als om softwaretools die het mogelijk maken om deze technieken toe te passen (SDC-tools). Het belang van en de interesse in deze technieken en tools nemen snel toe, niet alleen door de steeds verdergaande ontwikkelingen op het gebied van privacy (de eerdergenoemde invoering van de AVG in 2018), open data en big data, maar ook door het ontstaan van datalabs, data-innovatiehubs en andere samenwerkingsverbanden waarin datagedreven wordt gewerkt. Hierin spelen vraagstukken met betrekking tot het verantwoord verwerken van data die zowel privacybestendig als bruikbaar zijn een centrale rol.
SDC-technieken en -tools kunnen dataprofessionals ondersteunen bij het beschermen van privacygevoelige gegevens. Ze zijn gericht op het in kaart brengen van de onthullingsmogelijkheden op basis van de benoemde intrinsieke en extrinsieke risico’s en het elimineren van (direct of indirect) identificerende informatie, terwijl de datasets die gedeeld worden nuttig en bruikbaar blijven om innovatie te faciliteren. De technieken en tools kunnen gebruikt worden om de te publiceren dataset zodanig te transformeren dat de kans op privacy-onthullingen kleiner wordt. Daarnaast helpen ze bij het maken van de afweging tussen enerzijds privacy en anderzijds bruikbaarheid. De technieken en tools kunnen op zowel microdatasets als geaggregeerde datasets toegepast worden.
Het proces dat nodig is om data die gedeeld worden met derden door middel van SDC-technieken te beschermen tegen privacyinbreuken, bestaat uit verschillende fases. In de eerste stap wordt geïnventariseerd welke data, met wie en met welk doel gedeeld worden. In dit deel van het proces vindt een risicotaxatie plaats: welke risico’s komen er met het openen of delen van de dataset? Het daadwerkelijk beschermen van de data (de disclosure control) op basis van deze inventarisatie gebeurt daarna in twee stappen. Eerst worden de data bewerkt met behulp van SDC-methoden en vervolgens wordt beoordeeld of de uitgevoerde bewerkingen het gewenste effect hebben gehad. Pas als de data volgens deze beoordeling voldoende beschermd zijn, worden deze beschikbaar gesteld of gepubliceerd. Het kan dus zijn dat sommige stappen in het proces meerdere keren worden doorlopen.
De rol van achtergrondinformatie
Juist de eerste, voorbereidende stap is heel belangrijk. Zoals hierboven al beschreven is de rol van achtergrondinformatie groot en groeiende, terwijl deze informatie (de extrinsieke risicofactoren) in belangrijke mate bepaalt of er sprake is van mogelijke onthullingen. Statistische onthullingsmethoden kunnen namelijk op verschillende manieren voor privacyschendingen zorgen. Enerzijds kan het gaan om het achterhalen van de identiteit van een betrokkene en anderzijds om het achterhalen van (nieuwe) informatie over een betrokkene.
Voorbeelden mogelijke onthullingen
Stel dat de volgende tabel met informatie over de leerlingen in een klas wordt gedeeld. Deze tabel is afgeleid uit een microdatatabel waaruit de namen zijn verwijderd. Iemand die het enige zestienjarige meisje uit de klas kent, weet nu dat het eerste record in deze tabel (hieronder vetgedrukt) betrekking heeft op dit meisje, genaamd Anna. De identiteit van Anna wordt daarmee onthuld op basis van achtergrondkennis. Daarnaast wordt aanvullende informatie over Anna bekend, namelijk haar eindcijfer: een negen (hieronder vetgedrukt).
Stel dat vervolgens de volgende tabel met geaggregeerde informatie over de leerlingen in een klas wordt gedeeld. Iemand die het enige zestienjarige meisje uit de klas kent, weet nu welke cel in deze tabel (hieronder vetgedrukt) betrekking heeft op dit meisje. Ook in dit geval kan de identiteit van een van de betrokkenen in de tabel achterhaald worden op basis van achtergrondinformatie.
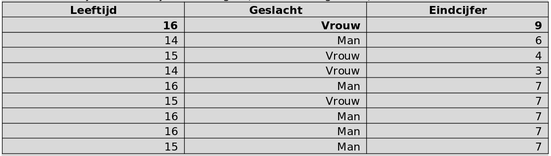

Beide soorten onthullingen kunnen optreden doordat het vaak mogelijk is om data uit verschillende bronnen met elkaar te verbinden. Om te kunnen bepalen of deze onthullingen daadwerkelijk kunnen optreden, is het daarom nodig de data-omgeving van de te publiceren dataset in kaart te brengen. Een belangrijke factor in de data-omgeving is de achtergrondinformatie die voor potentiele indringers beschikbaar is. Deze achtergrondinformatie wordt gevormd door de externe datasets en databases die naast de gepubliceerde dataset beschikbaar zijn en bij kunnen dragen aan het afleiden van de identiteit van betrokkenen. Enerzijds zijn dit eerdere publicaties met een soortgelijk doel en bereik als de nieuwe publicatie (bijvoorbeeld gelijksoortige of opeenvolgende publicaties van dezelfde of andere overheidsinstanties), anderzijds zijn dit databronnen uit een heel ander domein (bijvoorbeeld informatie op sociale netwerken).
Gelet hierop is daarom nodig de te delen data in hun omgeving te beschouwen. Pas dan kan bepaald worden of er privacybeschermingsmaatregelen nodig zijn. Het in kaart brengen van de data-omgeving omvat het beantwoorden van verschillende vragen: welke data worden met wie en waarom gedeeld? In welke context worden de data gedeeld en welke andere databronnen zijn daarin aanwezig? Welke indringers hebben mogelijk belang bij het onthullen van informatie en welke middelen hebben deze indringers tot hun beschikking?
Softwaretools
Om datasets te beschermen tegen onthullingen zijn verschillende SDC-methoden beschikbaar. Deze methoden beschermen de data ieder op een andere manier: elke methode transformeert de gegevens in de tabellen op een andere manier en heeft een ander effect op de bruikbaarheid van de gegevens. Afhankelijk van het vooraf bepaalde risico kan gegeven de data-omgeving, een geschikte methode gekozen worden.
Om het toepassen van SDC-methoden makkelijker te maken zijn verschillende softwaretools beschikbaar, bijvoorbeeld μ-ARGUS voor microdatasets en τ-ARGUS voor geaggregeerde datasets. Deze tools helpen in het proces door verschillende functionaliteiten aan te bieden. Zo is het mogelijk de te delen dataset te transformeren zodat de kans op onthullingen kleiner wordt. Ook is het mogelijk de kans op onthulling (voor en na de transformatie) te kwantificeren, en zo te controleren of het toepassen van SDC een gunstig effect heeft gehad op de privacy van de betrokkenen. Vervolgens is het mogelijk om te bepalen of de getransformeerde dataset nog steeds bruikbaar is voor het beoogde doel door het informatieverlies dat optreedt na het verhullen of onderdrukken van bepaalde gegevens te meten.
Hoewel sommige tools een grafische gebruikersinterface en een uitgebreide handleiding bieden, is het gebruik van SDC-tools over het algemeen complex. Het gebruik vraagt veel voorkennis op het gebied van SDC. De gebruikers hebben hier vaak aanvullende begeleiding bij nodig. De gebruiker moet onder andere inzicht hebben in het te publiceren datatype en de data-omgeving, zodat de juiste SDC-methode en parameters geselecteerd kunnen worden en de SDC-tool op een goede manier geconfigureerd kan worden. Daarnaast moet er rekening mee gehouden worden dat de bekende onthullingscenario’s gelden bij de huidige stand van de technologie. Er is daarom voortdurend onderzoek nodig om op de hoogte te blijven van mogelijke nieuwe scenario’s. Iets wat nu wellicht goed beschermd is, hoeft dit in de toekomst niet noodzakelijkerwijs meer te zijn, doordat de data-omgeving blijft groeien. SDC-tools bieden daarmee op zichzelf geen ‘kant-en-klare’ oplossing voor het beschermen van gevoelige gegevens.
Tot slot
Hoewel het toepassen van SDC-technieken en – tools dus noodzakelijk is voor het op een verantwoorde manier delen van data, is het gebruik ervan tegelijkertijd complex. Bij het WODC werken we daarom aan een procedure voor de praktische inzet van SDC-technieken en –tools en het inbedden ervan in de werkpraktijk van (overheids-)organisaties. Daarnaast is het nodig om kennis over SDC-technieken en –tools breder te verspreiden. We merken dat deze kennis op dit moment voornamelijk aanwezig is in het SDC-onderzoeksdomein. Deze kennis is echter niet alleen relevant voor de databeheerders en data-analisten die zich binnen (overheids-)organisaties al bezighouden met het anonimiseren, beschermen of openen van data, maar net zo belangrijk voor bestuurders die verantwoordelijk zijn voor privacy- en/of databeleid. Tevens is het voor professionals die datalabs en andere datagedreven samenwerkingsverbanden opzetten van belang om kennis op te bouwen over de kansen en beperkingen van deze technieken en -tools.
Susan van den Braak en Mortaza S. Bargh zijn werkzaam bij het Wetenschappelijk Onderzoek- en Documentatiecentrum (WODC)

Grappig dat deze materie al in 2018 door Thieu Kuys in zijn boek ‘Hoe symbolen onze privacy beschermen’ is beschreven: hij bewijst op basis van geanonimiseerde databases dat Jesse Klaver een 7 voor Nederlands op zijn eindexamenlijst heeft gehaald. En: je kunt uit statistische data die betrekking hebben op populaties van personen altijd informatie afleiden over geïdentificeerde of identificeerbare personen!
AVG beschermt op uitgebreide schaal het gebruik van gegevens. Toch is de wet te omzeilen door gebruikers toestemming te laten geven als hij een app wil gebruiken of een website bezoeken. Daarnaast worden aan het gebruik van algoritmes geen wettelijke eisen gesteld. Het is zelfs zo dat bijna altijd het gebruik onder het bedrijfsgeheim vallen. Eigenlijk zou er aan het gebruik van algoritmes vergelijkbare strenge eisen moeten worden gesteld als aan het gebruik van persoonsgegevens. Eisen zouden bijvoorbeeld kunnen worden gesteld aan het onderliggende model door bijvoorbeeld:
-aan het onderliggende model door modelvalidatie, zodat kan worden aangetoond dat het gebruikte model in een bepaalde mate deugt,
– aan de betrouwbaarheid van de gegevens in relatie met het doel waar ze voor worden gebruikt,
– voorkomen van afhankelijkheden tussen de gebruikte variabelen, bijvoorbeeld door regressie analyse, of geavanceerdere analyse methoden.
Dit zijn voorbeelden om de betrouwbaarheid van algoritmes zichtbaar te maken. Het is volgens mij belangrijk om toetsbare eisen aan algoritmes te stellen en dat in wetgeving op te nemen.