

Onbekendheid met AI vertroebelt debat

Wat is er eigenlijk slim aan een slim algoritme? Hoe zit het met willekeur? Weten we wel waarover we debatteren? iBestuur, zelf geregeld plek van debat, wil hier graag duiding aan geven. Dat doen we met een aantal ‘papieren’ colleges van professor Chris Verhoef.
Beeld: Chris Verhoef / Shutterstock
De zorgen zijn deels terecht. Maar ze zijn ook het gevolg van onbekendheid met het vakgebied, en het jargon veroorzaakt misverstanden. Prozaïsche namen als AI, neurale netwerken, machine learning, zelflerende algoritmes gaan een eigen leven leiden.
Gewoon statistiek
AI is veel minder mythisch en alomvattend dan velen denken. In werkelijkheid is AI niets meer dan statistiek. Statistiek is het vak dat uit onbetrouwbare gegevens betrouwbare conclusies trekt. Als voorbeeld een eenvoudig lezerspuzzeltje (voor de herhaalbaarheid is dit voorbeeld overgenomen en licht aangepast).
Stel dat bij sollicitanten op basis van hun cv en gesprekken scores worden gegeven. Voor zes sollicitanten is de uitslag bekend inclusief hun scores. In tabel 1 staan ook nog drie sollicitanten zonder uitslag. Neem de tabel even door zonder te gaan rekenen en voorspel de uitslag van die overige drie. Dan nu de oplossing: 7 en 9 gaan door en 8 heeft pech. Wat er net in uw hoofd gebeurde heet intelligentie en dat is na te bootsen. De kiem daarvoor werd gelegd in 1943 toen McCulloch en Pitts een wiskundig model voor eenvoudige zenuwcellen publiceerden1. Ze noemden dat een perceptron, maar niemand begreep die term dus de kranten hadden het al snel over een elektrisch brein. In 1958 demonstreerde de Amerikaanse marine het perceptronsysteem dat volgens de krantenkoppen van toen kon lezen, schrijven, vertalen en zelfs gezichten herkennen. Dat bleek toch wat tegen te vallen, en dat luidde de eerste zogenaamde AI-winter in. Zo hypecycled AI door de tijd heen, en zit het vak nu weer in een hausse.
| sollicitant | kennis | communicatieskills | uitslag |
| 1 | 20 | 90 | 1 | |
| 2 | 10 | 20 | 0 | |
| 3 | 30 | 40 | 0 | |
| 4 | 20 | 50 | 0 | |
| 5 | 80 | 50 | 1 | |
| 6 | 30 | 80 | 1 | |
| 7 | 30 | 85 | ? | |
| 8 | 40 | 50 | ? | |
| 9 | 85 | 40 | ? |
Tabel 1. Gegevens sollicitanten
Maar AI is en blijft statistiek en het werkt als volgt. Zet wat nepzenuwcellen bij elkaar; die kunnen op zich niets, net zoals een babybrein een onbeschreven blad is. Voor het sollicitatievoorbeeld doen we dat met zeven zenuwcellen die na het inleren de drie uitslagen feilloos voorspellen. Stap 1: geef het babybrein willekeurige beginwaarden. Het kan dus alleen onzin uitkramen, net zoals een baby het verschil tussen pap en poep niet kent. Stap 2: bereken de antwoorden met de eerste zes rijen uit de tabel. Stap 3: vergelijk die met de goede antwoorden. Nul kans dat die kloppen: de beginwaarden waren immers willekeurig. Stap 4: reken terug welke beginwaarde het meest miskleunde. Stap 5: pas die aan en ga weer naar Stap 2. Ga net zo lang door tot de fout tussen berekende uitkomst en het werkelijke antwoord is geminimaliseerd. Dit noemt men in de AI een zelflerend algoritme. Uit het voorbeeld blijkt hoe eenvoudig zo’n rekensommetje werkt, en computers zijn hier heel goed in. Daarom is ‘zelflerend’ niets meer dan een bombastische hyperbool voor het minimaliseren van een fout.
We gebruiken het sollicitatievoorbeeld om uit te leggen hoe deze statistiek werkt. In het echt is het net iets ingewikkelder, maar de principes zijn niet wezenlijk anders. Figuur 1 geeft het exacte model weer dat in 144 stapjes de slagingskansen voor sollicitanten voorspelt. Dat hadden ook 3 stapjes kunnen zijn, dat ligt gewoon aan de willekeurige beginwaarden. Halen we de drie nog niet beoordeelde sollicitanten door dit ingeleerde model dan krijgen we de volgende kansen voor de drie sollicitanten: 99.6 procent, 39.2 procent en 95.7 procent. Dit komt precies overeen met uw intuïtie! Het is dus statistiek met een knipoog naar het brein. Een betere term voor AI is daarom idiot savant.
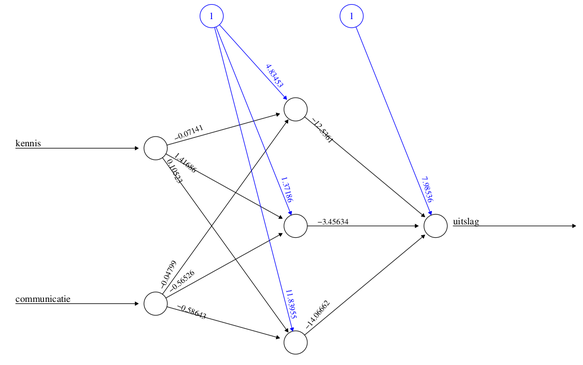
Figuur 1: Zeven zenuwcellen die slagingskansen van sollicitanten voorspellen
Transparantie versus willekeur
Wat je veelal hoort, en daar zit wel wat in, is dat de AI-algoritmes onbegrijpelijk zijn. Elk algoritme is te analyseren, en dus ook het zojuist afgeleide algoritme. In dit geval kunnen we het zelfs gewoon tekenen! Namelijk, omdat de uitkomst van het model bepaald wordt door twee scores, is dat driedimensionaal zichtbaar te maken. In de tweede figuur is dat weergegeven: de twee scores staan op de horizontale en diepte-as, en de door het algoritme voorspelde uitslag op de verticale as. Dit datagedreven model heeft een complexe structuur die je niet van te voren kunt bedenken, laat staan wiskundig kunt beschrijven. De complexiteit van de data geeft allerlei nuances weer die je met klassieke statistiek nooit zou vinden.
Statistiek is het vak dat uit onbetrouwbare gegevens betrouwbare conclusies trekt
De ingeleerde waarden van het AI-model in de eerste figuur hebben geen specifieke betekenis. Die worden enerzijds door willekeurige beginwaarden en anderzijds door de inleerdata bepaald. Niemand begrijpt dus waarom dit precies werkt. Als je het waarom wel wilt begrijpen, moet je eerst snappen wat het verband is, en dat verband op de data proberen te passen. Daarmee wordt een model transparant(er) maar niet noodzakelijk beter. Bijvoorbeeld: het zogenaamde WW-model van het UWV voorspelt WW’ers met de hoogste kans op regelovertreding. Vanwege de transparantie is gekozen voor een uitlegbaar model dat nagenoeg dezelfde voorspelkracht heeft als een AI-model.
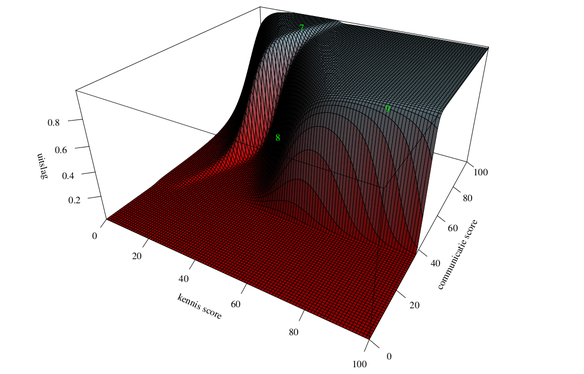
Figuur 2: Data gedreven verband tussen kennis, communicatie en uitslag
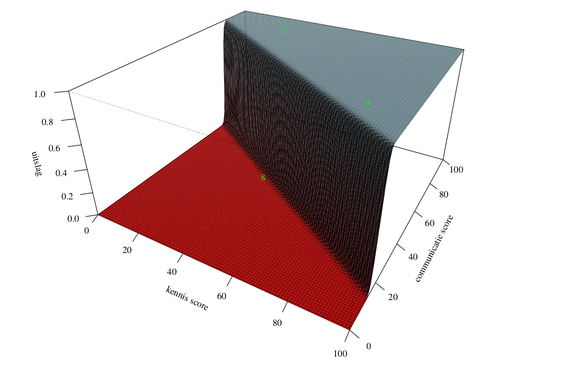
Figuur 3: Formule gedreven verband tussen kennis, communicatie en uitslag
In de derde figuur is een uitlegbaar model van het sollicitatievoorbeeld gemaakt: het bestaat uit één zenuwcel. De formule is eerst bedacht en daarna is de best mogelijke variant ervan op de gegevens gepast.
Ook dit model kunnen we tekenen omdat er twee scores zijn en een voorspelde uitslag. Het is een plat vlak dat in de hoeken is omgebogen. De groene cijfers zijn de voorspellingen voor sollicitanten 7, 8, 9: 100 procent, 0.13 procent en 99 procent, dus ook correct, maar veel minder genuanceerd dan het AI-model. Omdat het model relatief simpel is, maakt het meteen transparant hoe de twee factoren kennis en communicatie gewogen worden. Maar of het ook echt eerlijk is, is de vraag, want het AI-model laat meer nuance zien. Bijvoorbeeld sollicitant 8 maakt in het transparante model geen enkele kans, maar bij het datagedreven model ligt dat veel genuanceerder.
Dit voorbeeld laat goed zien dat verhoogde transparantie juist ook verhoogde willekeur mee kan brengen, terwijl meer complexiteit minder transparantie maar ook minder willekeur kan hebben. In het debat wordt juist betoogd dat AI leidt tot willekeur, maar transparantie kan dat net zo goed doen. Zeker als verbanden complex zijn, zou een klassiek en dus veelal uitlegbaar model eerder tot willekeur kunnen leiden dan een AI-model.
Slim of niet?
Je kunt niet altijd kiezen, sommige problemen hebben nu eenmaal geen eenvoudige wiskundige vorm. Neem bijvoorbeeld slimme algoritmes die hele teksten lijken te begrijpen. Daar heeft een netwerk van zenuwcellen meerwaarde, maar het is exact even dom als elk ander netwerk! Het vergt alleen wat voorbereiding. Verdeel eerst de tekst in evenzovele figuurtjes als er letters zijn en meet van elk figuurtje zo’n 15 aspecten. Kijk ook zelf welke letters het zijn en je hebt je rijtje getallen plus de correcte uitkomst net als de eerste zes sollicitanten. Deze getallen karakteriseren de letters. Zo is de I smaller dan de M, dus breedte en lengte zijn onderscheidend. De hoeveelheid zwart-wit ook: de I heeft minder zwart dan de M. Dus zo kun je deze twee letters al onderscheiden. Daarna neem je tienduizenden letters plus hun meetwaardes, voert dat aan een nog onbedorven babybreintje en na duizenden stapjes heb je een idiot savant voor nagenoeg feilloze letterherkenning. Daarom snapt zo’n algoritme niet werkelijk wat tekst is: het ziet geen verschil of er mam of main bedoeld wordt, maar als er een minivlekje op de tweede m zit, denkt het algoritme dat het twee letters zijn in plaats van een. Niet echt slim dus, maar wel fijn dat daarmee tekst doorzoekbaar wordt!
AI noch zegen noch vloek
Apocalyptische beelden over AI illustreren haarfijn dat statistiek moeilijk begrijpbaar is; en meer kennis en kunde ten behoeve van het maatschappelijk debat hard nodig is. Rooskleurige AI-vergezichten gaan het begrip niet verhogen. Het is van groot belang om het hoofd koel te houden bij dit debat. Je kunt natuurlijk niet zomaar de belangen van burgers schaden en hun privacy schenden, maar daar kun je algoritmes niet de schuld van geven. Als niemand precies kan weten waarom bepaalde verbanden bestaan, is dat op zichzelf nog geen reden om er daarom geen gebruik van te maken.
1 Warren S McCulloch andWalter Pitts. A logical calculus of the ideas immanent in nervous activity. The bulletin of mathematical biophysics, 5(4):115–133, 1943.
Dit artikel staat ook in iBestuur magazine 35

Als , zoals Verhoef concludeert, niemand precies kan weten waarom bepaalde verbanden bestaan, dan is het de vraag of een op AI gebaseerd model wel geschikt is als basis voor besluiten in het publieke domein. Probleem daarbij is dat het de wetenschappers op de betreffende terreinen ontbreekt aan voldoende kennis en inzicht op elkaars terrein om op basis van eigen kennis en kunde tot zo’n conclusie te komen. Als jurist heb ik dus geen oordeel over de juistheid van de conclusie van Verhoef, maar als we van de juistheid daarvan uitgaan, betekent dat dat we ons diepgaand zullen moeten gaan beraden over de toelaatbaarheid van op AI gebaseerde modellen als basis voor besluiten in het publieke domein.
Besluitvorming is hoe dan ook arbitrair. Juist juristen weten dat als geen ander. Het is de kunst om besluitvorming zodanig te onderbouwen dat er een acceptatie van de rechtmatigheid ontstaan. En dat geldt ook voor beslissingen in het publieke domein. Maar dan nog moet er een goed geborgd bezwaar mechanisme zijn. Daarom is een onafhankelijk rechter van groot belang. En het ontbreken van een correctief- of uitzonderingsmechanisme op de uitkomsten is het grootste risico met AI modellen.
Bij de kindertoeslag affaire was de vooraf bepaald dat fouten synoniem zijn voor fraude. En werd de bezwaarprocedure met opzet gefrustreerd. Als je je op die manier overlevert aan AI hebben we inderdaad een geweldig probleem. Maar kennelijk hebben we dat dus nu ook al want het signaleringsalgoritme van de belastingdienst zou ik niet als AI willen kenmerken.
“[N]et zoals een babybrein een onbeschreven blad is.” Het artikel verandert niet wezenlijk als dit zinsdeel wordt verwijderd (gelukkig maar!) Miljoenen jaren evolutie maakten van het babybrein een nogal goed op de omgeving voorbereid onderdeel van de baby als geheel. Maar gek genoeg, als je in aanmerking neemt dat het brein voor een belangrijk deel een statistiekmachine is, houdt het brein niet van statistiek, meer van vuistregeltjes, da’s makkelijker. Zie Sapolsky’s Behave en Kahneman’s Thinking fast and slow voor veel leuke details :-)