

Lensink verzorgde begin deze maand een presentatie tijdens het Symposium E-Discovery 2024. In oktober moet er een enorme berg 'schoongemaakte data' klaar staan om de eerste training van het model te gaan starten. "Het liefst zouden wij zo'n 500 miljard tokens willen hebben," vertelt ze. "Het model wordt alleen maar beter als we zoveel mogelijk verschillende datatypen in kunnen zetten."
Wie wil zijn data delen met GPT-NL?

In oktober wordt een start gemaakt met de training van GPT-NL, dat momenteel ontwikkeld wordt door TNO, NFI en SURF. Productowner Saskia Lensink van TNO roept partijen op usescases en data te delen met het project. "GTP-NL is een echt Nederlands initiatief. Het kan alleen een succes worden als we er met z'n allen de schouders onder zetten en zoveel mogelijk data in dat model gaan stoppen."
GPT-NL, het Nederlandse Large Language Model, gaat voor de helft uit het Nederlands woorden bestaan en voor de helft uit het Engels woorden. "En vermoedelijk ook nog wat codeertaal, er zijn aanwijzingen het model dan beter kan redeneren." Het moet een model worden waar je echt wat mee kan. "Een model waarmee je teksten kunt laten samenvatten, dat je kan ondersteunen in het versimpelen van taalgebruik." Het model moet het werk efficiënter en effectiever kunnen maken.
Schone data
De dataset wordt vanaf de grond af opgebouwd, vertelt Lensink. "Dat doen we op zo’n manier dat we alleen data meenemen die we mogen gebruiken. Alle persoonsgegevens halen we eruit. Daarbij zin we zo transparant mogelijk over de keuzes die we daarin maken." Het model wordt gebouwd in lijn met de huidige en de aankomende wet en regelgeving, waarbij ze verwijst naar regelgeving over intellectueel eigendom, bescherming persoonsgegevens (AVG) en bijvoorbeeld de AI-Act.
"We willen alleen data inzetten die we mogen gebruiken. Dat kan gaan om data van Creative Commons licensee en Creative Commons Zero. Maar we kunnen ook afspraken maken met datahouders."
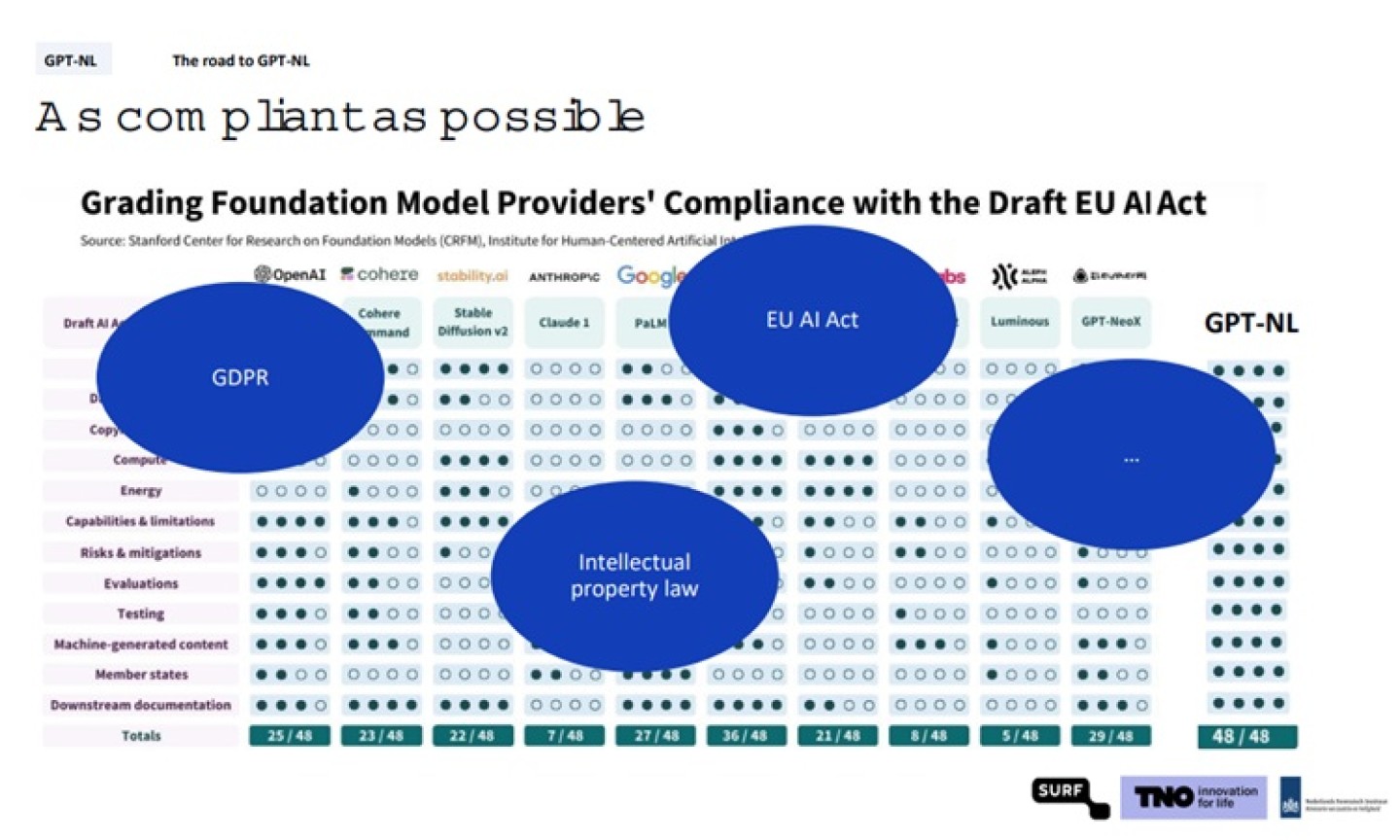
Diverse dataset
"We willen er ook heel graag voor zorgen dat onze technologie, zo min mogelijk last heeft van bias." Maar dat kan alleen als je er veel en zo divers mogelijke data in stopt of dat de dataset zo divers mogelijk wordt gemaakt. Waarschijnlijk wordt de dataset dan uitgebreid met synthetische data, zegt Lensink.
Initiatieven in Europa
Nederland is niet het enige Europese land dat een eigen LLM ontwikkeld. Leusink wijst op verschillende open source-initiatieven, Open GPT-X in Duitsland, GPT Zweden en de 'Alliance for Language Technolgies (ALT) EDIC'. In Spanje wordt de Barcelona Supercomputer ingezet om diverse taalmodellen te trainen. Vanuit Europa wordt geld beschikbaar gesteld om meer onderzoek naar taaltechnologie mogelijk te maken.
Oproep
Het belangrijkste van GPT-NL is dat het voor en door Nederland wordt gebouwd, zegt Lensink. "Daarom zijn we altijd op zoek naar mensen die use cases voor ons hebben. Het kan alleen een succes worden als we er met z'n allen de schouders onder zetten en zoveel mogelijk data in dat model gaan stoppen. Dus data providers, mensen die hun data willen delen, je bent altijd van harte welkom. Neem vooral contact met ons op!
Meedoen? Je kan meedoen als Use Case provider, Data provider of End user. Mail saskia.lensink@tno.nl
Waarom een Nederlandse LLM?
- Buitenlandse taalmodellen zijn niet getraind om grote hoeveelheden Nederlandse data. Ze kunnen dus ook niet zo goed omgaan met typisch Nederlandse concepten en culturele uitingen.
- Modellen, als ChatGPT, schenden op grote schaal de privacy en intellectuele eigendomsrechten.
- Bepaalde modellen voldoen niet aan Europese waarden en normen.
Lees ook:

Plaats een reactie
U moet ingelogd zijn om een reactie te kunnen plaatsen.