

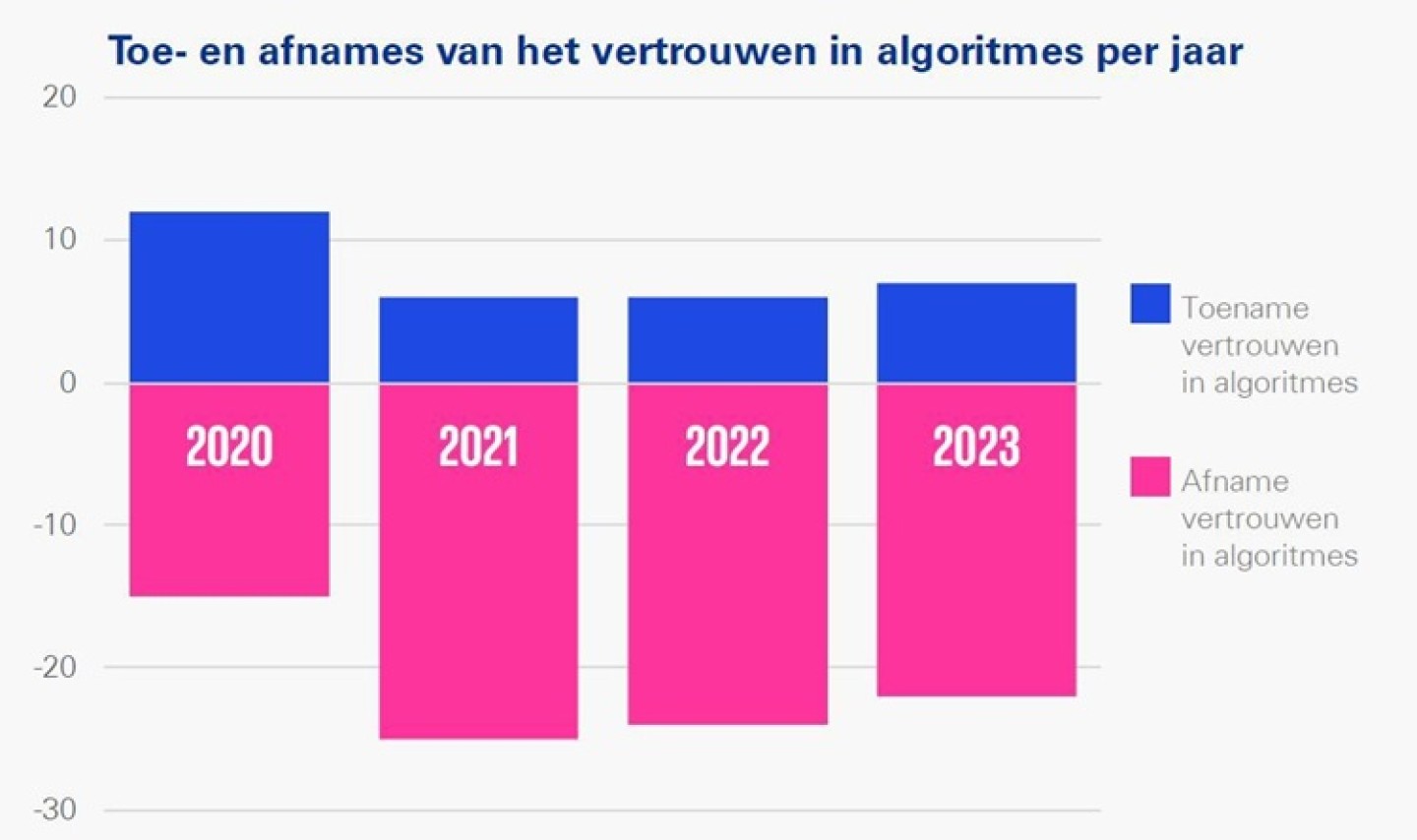
KPMG: Vertrouwen in algoritmes blijft dalen

De bekendheid met algoritmes onder Nederlanders neemt toe, maar vertrouwen in het gebruik van algoritmes neemt opnieuw af, blijkt uit de nieuwste Algoritmemonitor van KPMG.
Accountants- en adviesbureau KPMG onderzoekt elk jaar hoe Nederlanders aankijken tegen algoritmes. Bij de eerste meting in 2019 was 46% van de Nederlanders bekend met algoritmes. Vorig jaar was dat gegroeid naar 63%. Dit jaar groeide de bekendheid met algoritmes door naar 75% blijkt uit de Algoritme Vertrouwensmonitor 2023. 1044 Nederlanders, in de leeftijdscategorie van 18 t/m 75 jaar, hebben deelgenomen aan het onderzoek.
Bron: KPMG
De mate waarin Nederlanders bekend zijn met algoritmes verschilt wel, waarbij met name opleidingsniveau een rol speelt. Jongeren die een theoretisch opleiding hebben afgerond zijn goed op de hoogte, 65-plussers met een praktische opleiding zjn er het minst bekend mee.
Wantrouwen richting overheid en financiële wereld
In de studie komt naar voren dat het wantrouwen tegenover het gebruik van algoritmes door de overheid is gegroeid. De helft van de respondenten denkt dat overheden niet altijd eerlijk en transparant zijn over de manier waarop ze algoritmes inzetten. Het feit dat overheidsinstellingen regelmatig negatief in het nieuws komen door foutief gebruik van algoritmes draagt hier zeker bij aan het negatieve beeld.
Met de publicatie in een algoritmeregister kan de overheid mogelijk weer wat het vertrouwen vertrouwen opbouwen. Een ruime meerderheid (72%) deelnemers aan het onderzoek geeft aan dat het voor organisaties verplicht moeten worden om informatie over hun algoritmes te publiceren in een algoritmeregister.
Meer informatie en toezicht nodig
De overgrote meerderheid van de respondenten (81%) laat weten dat toezicht op algoritmes wenselijk is. Deze taak zou volgens de meeste ondervraagden moeten worden uitgevoerd door onafhankelijke, derde partijen.
Volgens KPMG zou de overheid ook meer moeten toen aan educatie. “Burgers moeten beter worden geïnformeerd over wat algoritmes zijn en wat ze allemaal kunnen. Dat moet misschien wel in het onderwijs beginnen. Zo kan het vertrouwen onder de Nederlandse bevolking in algoritmes gaan groeien,” aldus Frank van Praat die leidinggeeft aan het Responsible AI-team van KPMG.

Plaats een reactie
U moet ingelogd zijn om een reactie te kunnen plaatsen.
Waarom zou je het willen? Natuurlijk is het nodig om de kwaliteit van algoritmes te verifiëren om hun betrouwbaarheid, nauwkeurigheid en efficiëntie te waarborgen, maar laten we dan de emotie erbuiten laten. Algoritmes bestaan al eeuwen. Kies gewoon openlijk voor een paar wetenschappelijk bewezen methoden die gebruikt worden in de computerwetenschap en software engineering en voer die ook openlijk uit. Net als bij wetenschappelijke artikelen, worden algoritmes vaak geëvalueerd door vakgenoten die expertise hebben in het relevante domein. Dit proces kan ontwerpfouten, logische fouten en andere problemen aan het licht brengen. (peer review). Unit Testing is een methode waarbij individuele componenten van een algoritme geïsoleerd worden getest om zeker te zijn dat elk deel correct functioneert. Integration Testing is een test methode waarbij de individuele componenten, na Unit Testing, worden samengevoegd en als één groep getest om te controleren op problemen met de interacties tussen verschillende delen van het algoritme. Validation Testing is een test methode waaronder een algoritme wordt getest met vooraf bepaalde input om te kijken of de output overeenkomt met de verwachte resultaten. Je zou Formele Verifacatie kunnen proberen: een wiskundige aanpak om te bewijzen of een algoritme overeenkomt met zijn specificatie. Het is een grondige aanpak die vaak wordt gebruikt in kritieke systemen, zoals luchtvaart- en medische software. We kennen Statistische Analyse: bij stochastische of probabilistische algoritmen worden statistische methoden gebruikt om de prestaties over een groot aantal trials te analyseren. Dan bestaat er zoiets als Code Review, een systematisch onderzoek van de broncode door een of meer personen om fouten te vinden en de algehele codekwaliteit te verbeteren. Static Code Analysis zet automatische tools in om broncode te analyseren zonder dat deze wordt uitgevoerd. Deze tools kunnen helpen bij het identificeren van veelvoorkomende fouten, zoals syntaxfouten, typefouten, geheugenlekken, etc. Bij Dynamic Analysis wordt het algoritme uitgevoerd in een realtime omgeving om het gedrag ervan te analyseren en problemen op te sporen die niet gedetecteerd worden tijdens static analysis. Bij Stress Testing zorg je dat het algoritme wordt onderworpen aan extreme omstandigheden (zoals hoge belasting, hoge snelheid van verzoeken, of beperkte middelen) om de robuustheid en foutentolerantie te testen. Simulatie van het algoritme met behulp van modellen kan helpen bij het begrijpen van de werking in complexe scenario's die moeilijk fysiek te reproduceren zijn. Dan heb je nog Fuzz Testing, waarbij de input van grote hoeveelheden random data ("fuzz") wordt gebruikt om het algoritme te testen en te controleren op onverwachte gedrag of crashes.
Al deze methoden kunnen afzonderlijk of in combinatie worden gebruikt, afhankelijk van de complexiteit van het algoritme en de vereisten van het systeem waarin het wordt geïmplementeerd.
Kortom, mogelijkheden genoeg, maar DOE wat en leg uit WAT je doet, maar laten we die emotie achterwege laten. 'Er moet 'iets' gebeuren aan algoritmes, klinkt net als: ik geloof niet, maar ik geloof wel dat er 'iets' is. Geef mij dan maar Russel's Tea Pot.